
A vector database is a bunch of data the place every bit of data is saved as a (numerical) vector. A vector represents an object or entity, equal to an image, particular person, place and so forth. inside the abstract N-dimensional home.
Vectors, as outlined inside the earlier chapter, are important for determining how entities are related and could be utilized to hunt out their semantic similarity. This can be utilized in numerous strategies for SEO – equal to grouping associated key phrases or content material materials (using kNN).
On this text, we’ll be taught numerous strategies to make use of AI to SEO, along with discovering semantically associated content material materials for internal linking. This could help you refine your content material materials method in an interval the place search engines like google like google an increasing number of rely on LLMs.
You’ll be able to even study a earlier article on this sequence about learn the way to find key phrase cannibalization using OpenAI’s textual content material embeddings.
Let’s dive in proper right here to begin out developing the thought of our software program.
Understanding Vector Databases
You in all probability have tons of of articles and wish to find the closest semantic similarity to your objective query, you presumably can’t create vector embeddings for all of them on the fly to match, because it’s extraordinarily inefficient.
For that to happen, we’d want to generate vector embeddings solely as quickly as and maintain them in a database we’ll query and uncover the closest match article.
And that is what vector databases do: They’re explicit types of databases that retailer embeddings (vectors).
When you query the database, not like typical databases, they perform cosine similarity match and return vectors (on this case articles) closest to a distinct vector (on this case a key phrase phrase) being queried.
Here is what it seems to be like like:
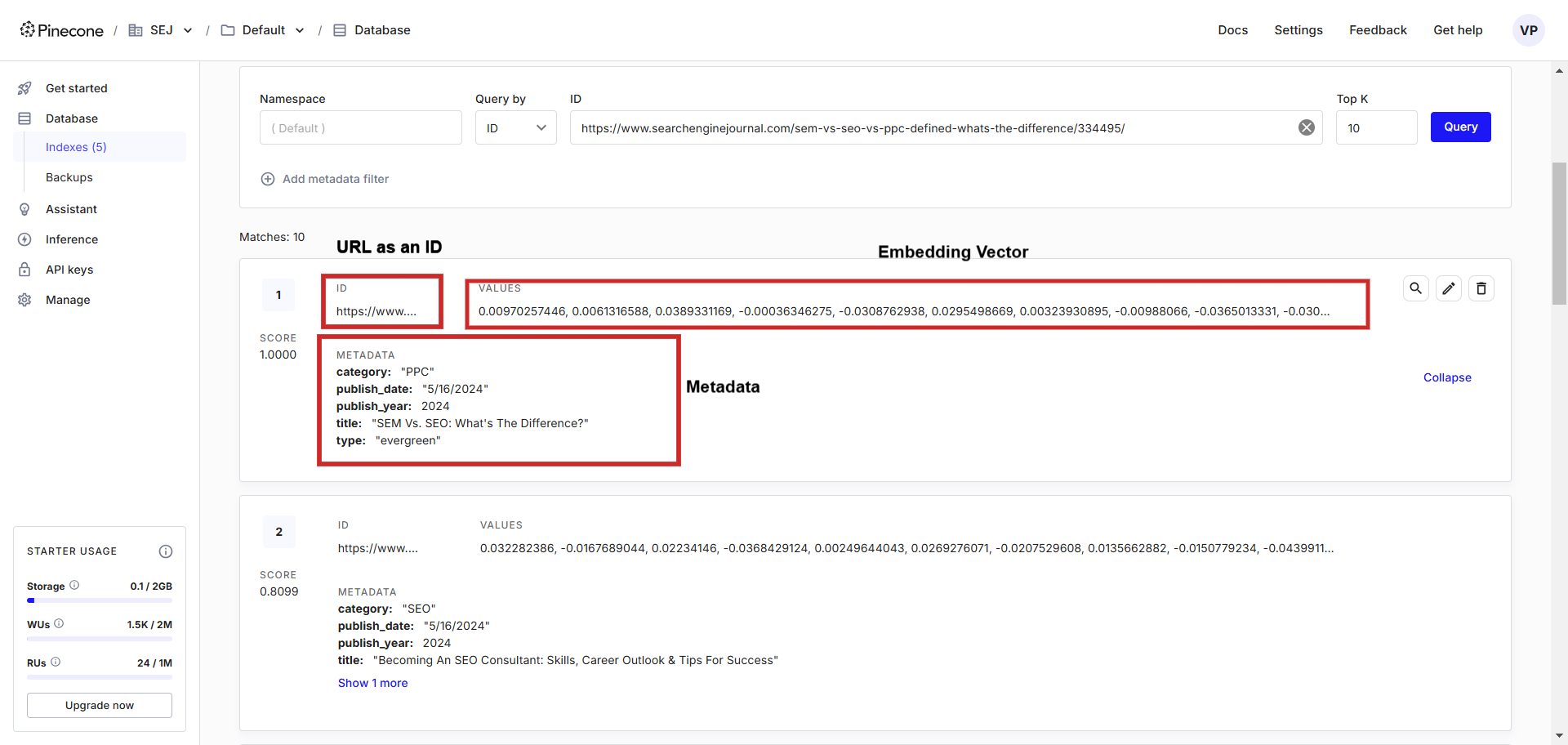 Textual content material embedding report occasion inside the vector database.
Textual content material embedding report occasion inside the vector database.Inside the vector database, you presumably can see vectors alongside metadata saved, which we’ll merely query using a programming language of our various.
On this text, we’ll in all probability be using Pinecone ensuing from its ease of understanding and ease of use, nonetheless there are completely different suppliers equal to Chroma, BigQuery, or Qdrant you can want to try.
Let’s dive in.
1. Create A Vector Database
First, register an account at Pinecone and create an index with a configuration of “text-embedding-ada-002” with ‘cosine’ as a metric to measure vector distance. Chances are you’ll title the index one thing, we’re going to title itarticle-index-all-ada‘.
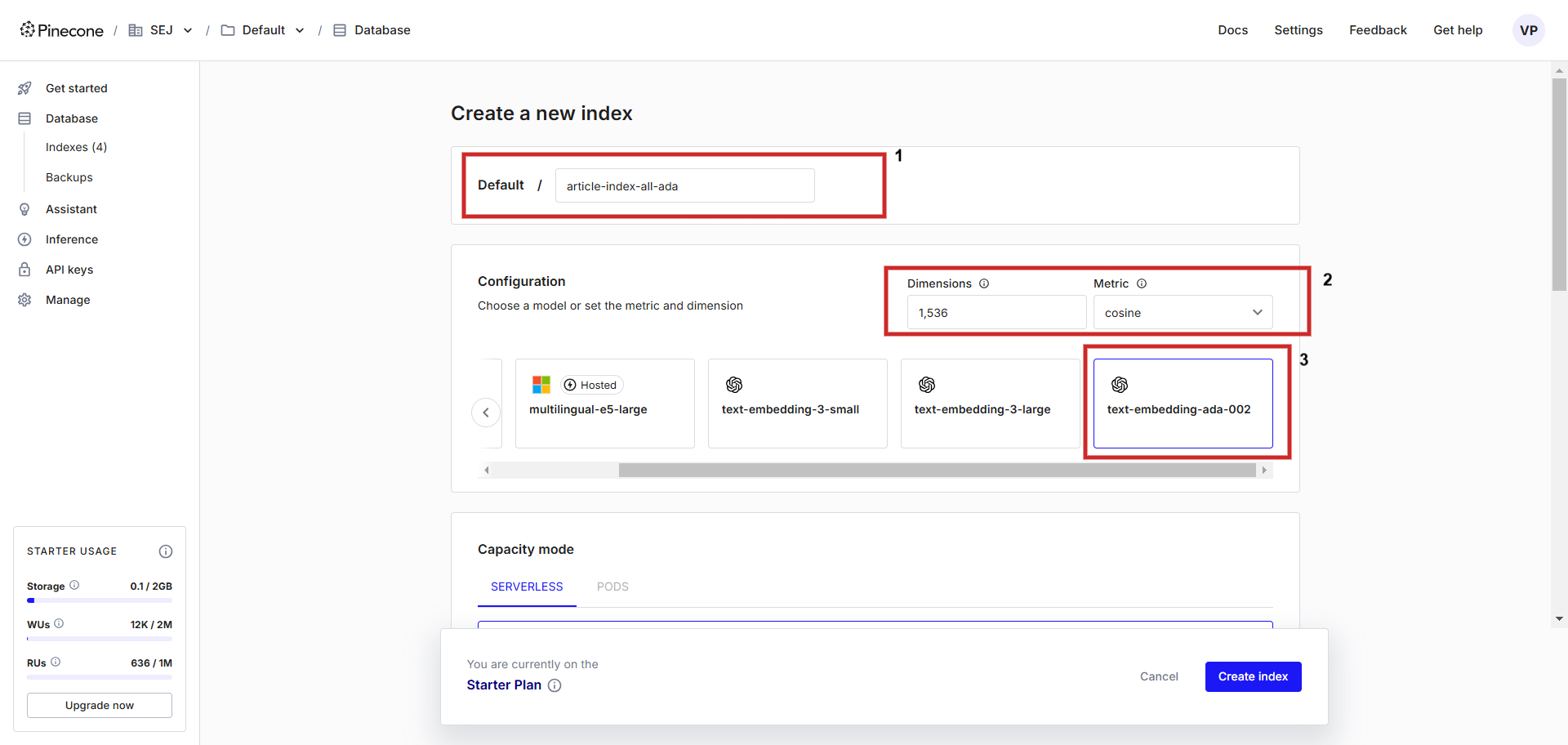 Making a vector database.
Making a vector database.This helper UI is only for serving to you thru the setup, in case you want to retailer Vertex AI vector embedding it is worthwhile to set ‘dimensions’ to 768 inside the config show display manually to match default dimensionality and you could retailer Vertex AI textual content material vectors (you presumably can set dimension value one thing from 1 to 768 to keep away from losing memory).
On this text we’re going to uncover methods to make use of OpenAi’s ‘text-embedding-ada-002’ and Google’s Vertex AI ‘text-embedding-005’ fashions.
As quickly as created, we would like an API key to have the flexibility to hook up with the database using a bunch URL of the vector database.
Subsequent, you’ll have to make use of Jupyter Pocket ebook. If you happen to occur to don’t have it put in, adjust to this data to place in it and run this command (beneath) afterward in your PC’s terminal to place in all important packages.
pip arrange openai google-cloud-aiplatform google-auth pandas pinecone-client tabulate ipython numpyAnd take into account ChatGPT could also be very useful everytime you encounter factors all through coding!
2. Export Your Articles From Your CMS
Subsequent, we’ve to place collectively a CSV export file of articles out of your CMS. If you happen to occur to make use of WordPress, you want to use a plugin to do personalised exports.
As our remaining goal is to assemble an internal linking software program, we’ve to find out which data should be pushed to the vector database as metadata. Principally, metadata-based filtering acts as an extra layer of retrieval steering, aligning it with the general RAG framework by incorporating exterior knowledge, which is ready to help to boost retrieval prime quality.
For instance, if we’re modifying an article on “PPC” and have to insert a hyperlink to the phrase “Key phrase Evaluation,” we’ll specify in our software program that “Class=PPC.” This could allow the software program to query solely articles all through the “PPC” class, ensuring right and contextually associated linking, or we’d have to hyperlink to the phrase “newest google change” and limit the match solely to data articles by using ‘Type’ and printed this yr.
In our case, we’ll in all probability be exporting:
- Title.
- Class.
- Type.
- Publish Date.
- Publish 12 months.
- Permalink.
- Meta Description.
- Content material materials.
To help return the simplest outcomes, we might concatenate the title and meta descriptions fields as they’re the simplest illustration of the article that we’ll vectorize and best possible for embedding and internal linking capabilities.
Using the overall article content material materials for embeddings would possibly cut back precision and dilute the relevance of the vectors.
This happens because of a single big embedding tries to characterize numerous issues lined inside the article directly, leading to a a lot much less centered and associated illustration. Chunking strategies (splitting the article by pure headings or semantically important segments) should be utilized, nonetheless these shouldn’t the primary goal of this textual content.
Proper right here’s the sample export file you presumably can acquire and use for our code sample beneath.
2. Inserting OpenAi’s Textual content material Embeddings Into The Vector Database
Assuming you already have an OpenAI API key, this code will generate vector embeddings from the textual content material and insert them into the vector database in Pinecone.
import pandas as pd
from openai import OpenAI
from pinecone import Pinecone
from IPython.present import clear_output
# Setup your OpenAI and Pinecone API keys
openai_client = OpenAI(api_key='YOUR_OPENAI_API_KEY') # Instantiate OpenAI shopper
pinecone = Pinecone(api_key='YOUR_PINECON_API_KEY')
# Join with an current Pinecone index
index_name = "article-index-all-ada"
index = pinecone.Index(index_name)
def generate_embeddings(textual content material):
"""
Generates an embedding for the given textual content material using OpenAI's API.
Returns None if textual content material is invalid or an error occurs.
"""
try:
if not textual content material or not isinstance(textual content material, str):
elevate ValueError("Enter textual content material ought to be a non-empty string.")
finish end result = openai_client.embeddings.create(
enter=textual content material,
model="text-embedding-ada-002"
)
clear_output(wait=True) # Clear output for a up to date present
if hasattr(finish end result, 'data') and len(finish end result.data) > 0:
print("API Response:", finish end result)
return finish end result.data[0].embedding
else:
elevate ValueError("Invalid response from the OpenAI API. No data returned.")
apart from ValueError as ve:
print(f"ValueError: {ve}")
return None
apart from Exception as e:
print(f"An error occurred whereas producing embeddings: {e}")
return None
# Load your articles from a CSV
df = pd.read_csv('Sample Export File.csv')
# Course of each article
for idx, row in df.iterrows():
try:
clear_output(wait=True)
content material materials = row["Content"]
vector = generate_embeddings(content material materials)
if vector is None:
print(f"Skipping article ID {row['ID']} ensuing from empty or invalid embedding.")
proceed
index.upsert(vectors=[
(
row['Permalink'], # Distinctive ID
vector, # The embedding
{
'title': row['Title'],
'class': row['Category'],
'kind': row['Type'],
'publish_date': row['Publish Date'],
'publish_year': row['Publish Year']
}
)
])
apart from Exception as e:
clear_output(wait=True)
print(f"Error processing article ID {row['ID']}: {str(e)}")
print("Embeddings are effectively saved inside the vector database.")
It is important to create a pocket ebook file and duplicate and paste it in there, then add the CSV file ‘Sample Export File.csv’ within the an identical folder.
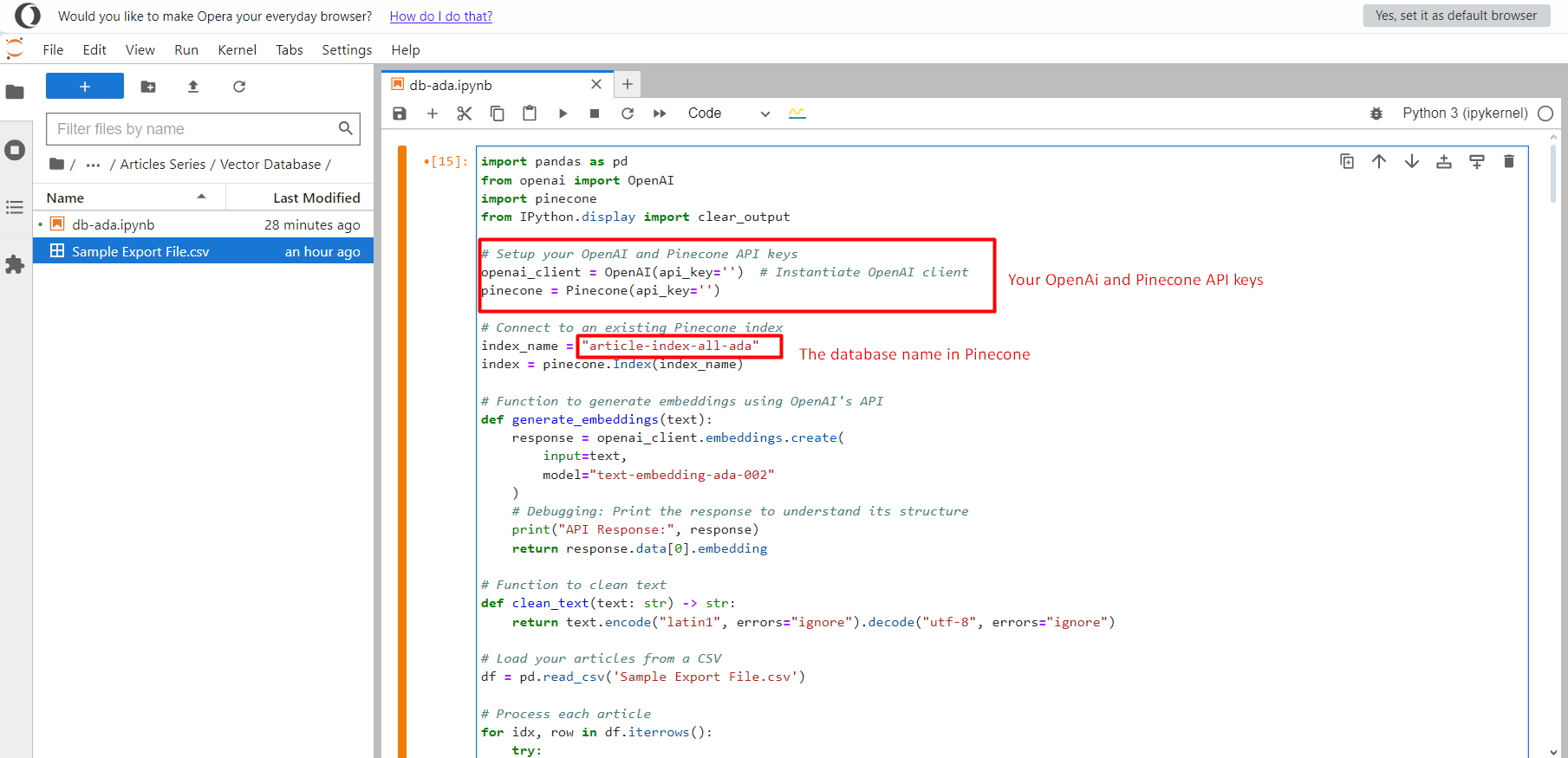 Jupyter problem.
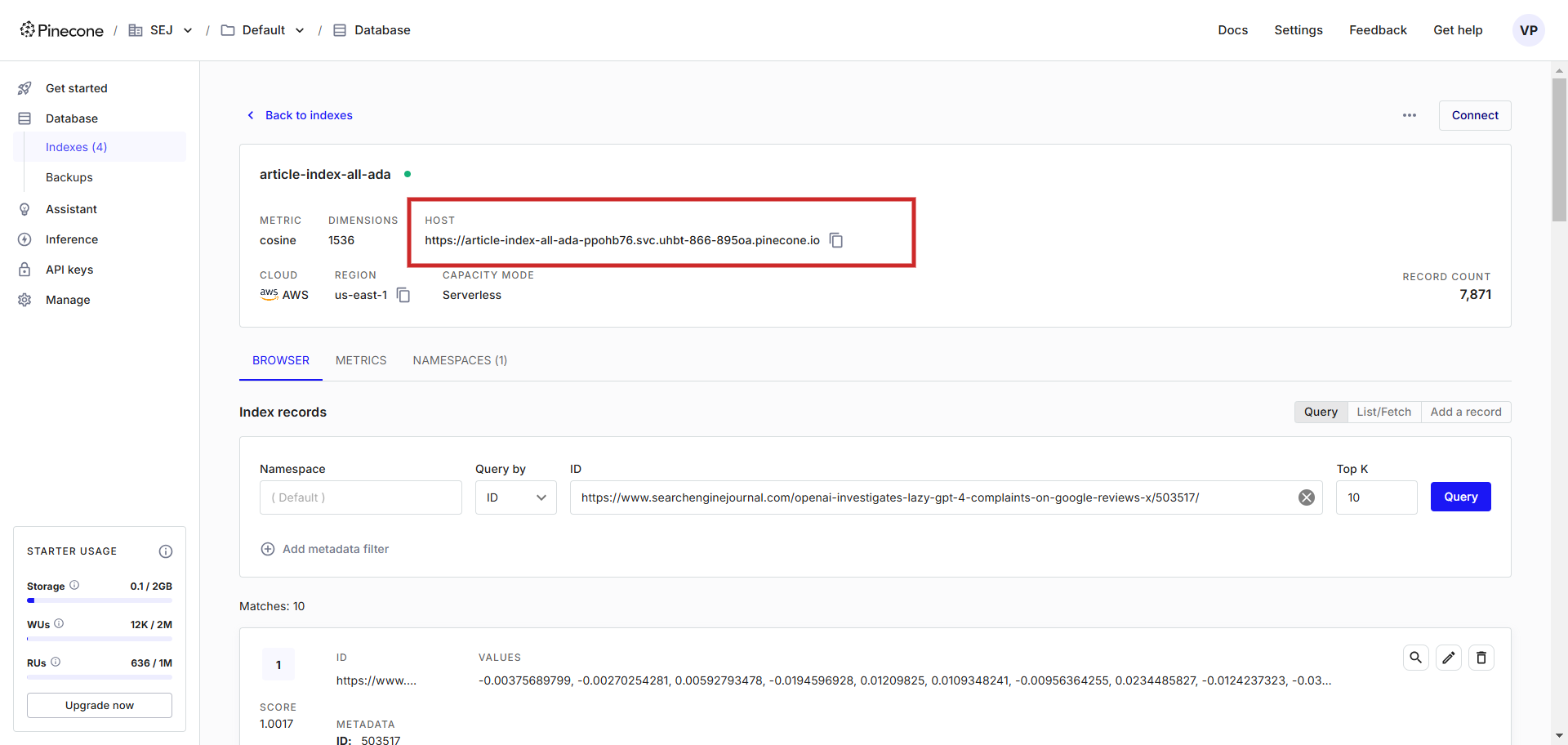
Jupyter problem.As quickly as carried out, click on on on the Run button and it will start pushing all textual content material embedding vectors into the index article-index-all-ada we created in the 1st step.
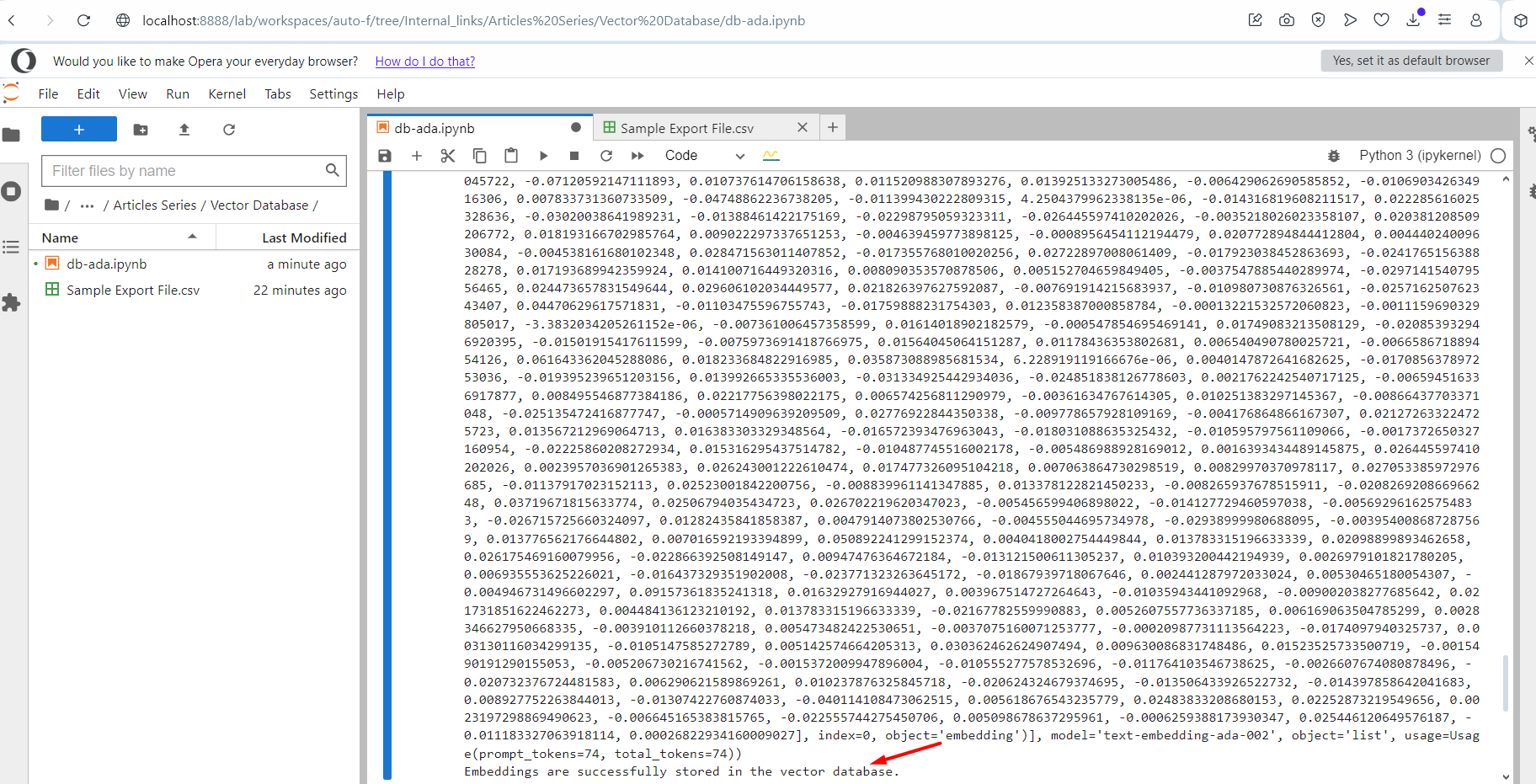 Working the script.
Working the script.You’ll notice an output log textual content material of embedding vectors. As quickly as accomplished, it will current the message on the end that it was effectively accomplished. Now go and check your index inside the Pinecone and you’ll notice your data are there.
3. Discovering An Article Match For A Key phrase
Okay now, let’s try to find an article match for the Key phrase.
Create a model new pocket ebook file and duplicate and paste this code.
from openai import OpenAI
from pinecone import Pinecone
from IPython.present import clear_output
from tabulate import tabulate # Import tabulate for desk formatting
# Setup your OpenAI and Pinecone API keys
openai_client = OpenAI(api_key='YOUR_OPENAI_API_KEY') # Instantiate OpenAI shopper
pinecone = Pinecone(api_key='YOUR_OPENAI_API_KEY')
# Join with an current Pinecone index
index_name = "article-index-all-ada"
index = pinecone.Index(index_name)
# Function to generate embeddings using OpenAI's API
def generate_embeddings(textual content material):
"""
Generates an embedding for a given textual content material using OpenAI's API.
"""
try:
if not textual content material or not isinstance(textual content material, str):
elevate ValueError("Enter textual content material ought to be a non-empty string.")
finish end result = openai_client.embeddings.create(
enter=textual content material,
model="text-embedding-ada-002"
)
# Debugging: Print the response to know its building
clear_output(wait=True)
#print("API Response:", finish end result)
if hasattr(finish end result, 'data') and len(finish end result.data) > 0:
return finish end result.data[0].embedding
else:
elevate ValueError("Invalid response from the OpenAI API. No data returned.")
apart from ValueError as ve:
print(f"ValueError: {ve}")
return None
apart from Exception as e:
print(f"An error occurred whereas producing embeddings: {e}")
return None
# Function to query the Pinecone index with key phrases and metadata
def match_keywords_to_index(key phrases):
"""
Matches a list of key phrases to the closest article inside the Pinecone index, filtering by metadata dynamically.
"""
outcomes = []
for keyword_pair in key phrases:
try:
clear_output(wait=True)
# Extract the important thing phrase and sophistication from the sub-array
key phrase = keyword_pair[0]
class = keyword_pair[1]
# Generate embedding for the current key phrase
vector = generate_embeddings(key phrase)
if vector is None:
print(f"Skipping key phrase '{key phrase}' ensuing from embedding error.")
proceed
# Query the Pinecone index for the closest vector with metadata filter
query_results = index.query(
vector=vector, # The embedding of the important thing phrase
top_k=1, # Retrieve solely the closest match
include_metadata=True, # Embrace metadata inside the outcomes
filter={"class": class} # Filter outcomes by metadata class dynamically
)
# Retailer the closest match
if query_results['matches']:
closest_match = query_results['matches'][0]
outcomes.append({
'Key phrase': key phrase, # The searched key phrase
'Class': class, # The category used for filtering
'Match Score': f"{closest_match['score']:.2f}", # Similarity ranking (formatted to 2 decimal areas)
'Title': closest_match['metadata'].get('title', 'N/A'), # Title of the article
'URL': closest_match['id'] # Using 'id' as a result of the URL
})
else:
outcomes.append({
'Key phrase': key phrase,
'Class': class,
'Match Score': 'N/A',
'Title': 'No match found',
'URL': 'N/A'
})
apart from Exception as e:
clear_output(wait=True)
print(f"Error processing key phrase '{key phrase}' with class '{class}': {e}")
outcomes.append({
'Key phrase': key phrase,
'Class': class,
'Match Score': 'Error',
'Title': 'Error occurred',
'URL': 'N/A'
})
return outcomes
# Occasion utilization: Uncover matches for an array of key phrases and courses
key phrases = [["SEO Tools", "SEO"], ["TikTok", "TikTok"], ["SEO Consultant", "SEO"]] # Substitute collectively together with your key phrases and courses
matches = match_keywords_to_index(key phrases)
# Present the ends in a desk
print(tabulate(matches, headers="keys", tablefmt="fancy_grid"))
We’re searching for a match for these key phrases:
- SEO Devices.
- TikTok.
- SEO Advisor.
And that’s the finish end result we get after executing the code:
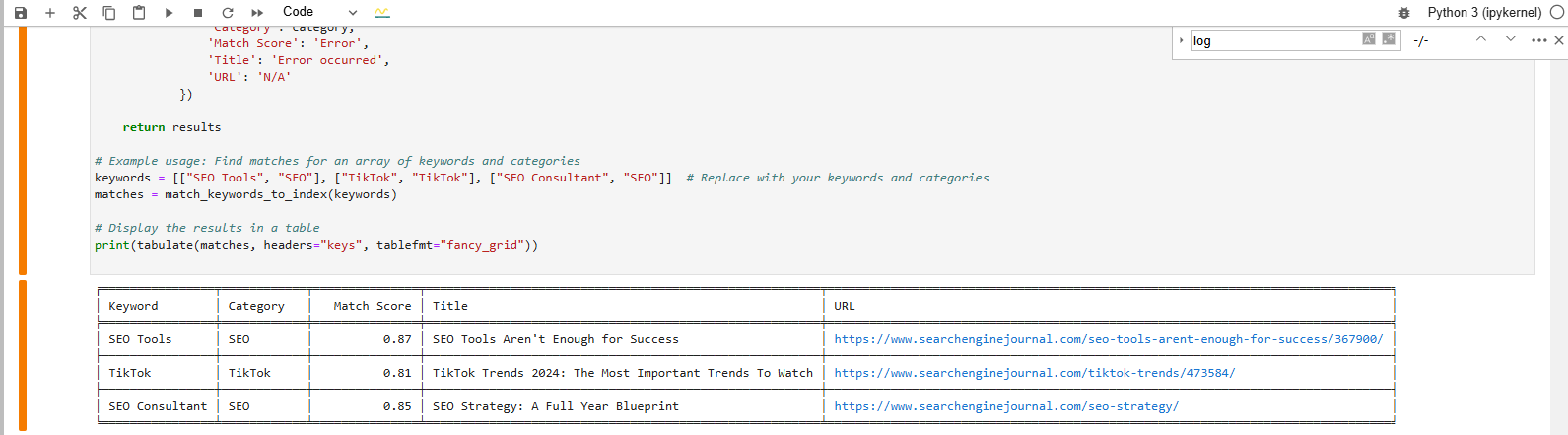 Uncover a match for the important thing phrase phrase from vector database
Uncover a match for the important thing phrase phrase from vector databaseThe desk formatted output on the bottom reveals the closest article matches to our key phrases.
4. Inserting Google Vertex AI Textual content material Embeddings Into The Vector Database
Now let’s do the an identical nonetheless with Google Vertex AI ‘text-embedding-005’embedding. This model is notable because of it’s developed by Google, powers Vertex AI Search, and is especially educated to take care of retrieval and query-matching duties, making it well-suited for our use case.
Chances are you’ll even assemble an internal search widget and add it to your web page.
Start by signing in to Google Cloud Console and create a problem. Then from the API library uncover Vertex AI API and permit it.
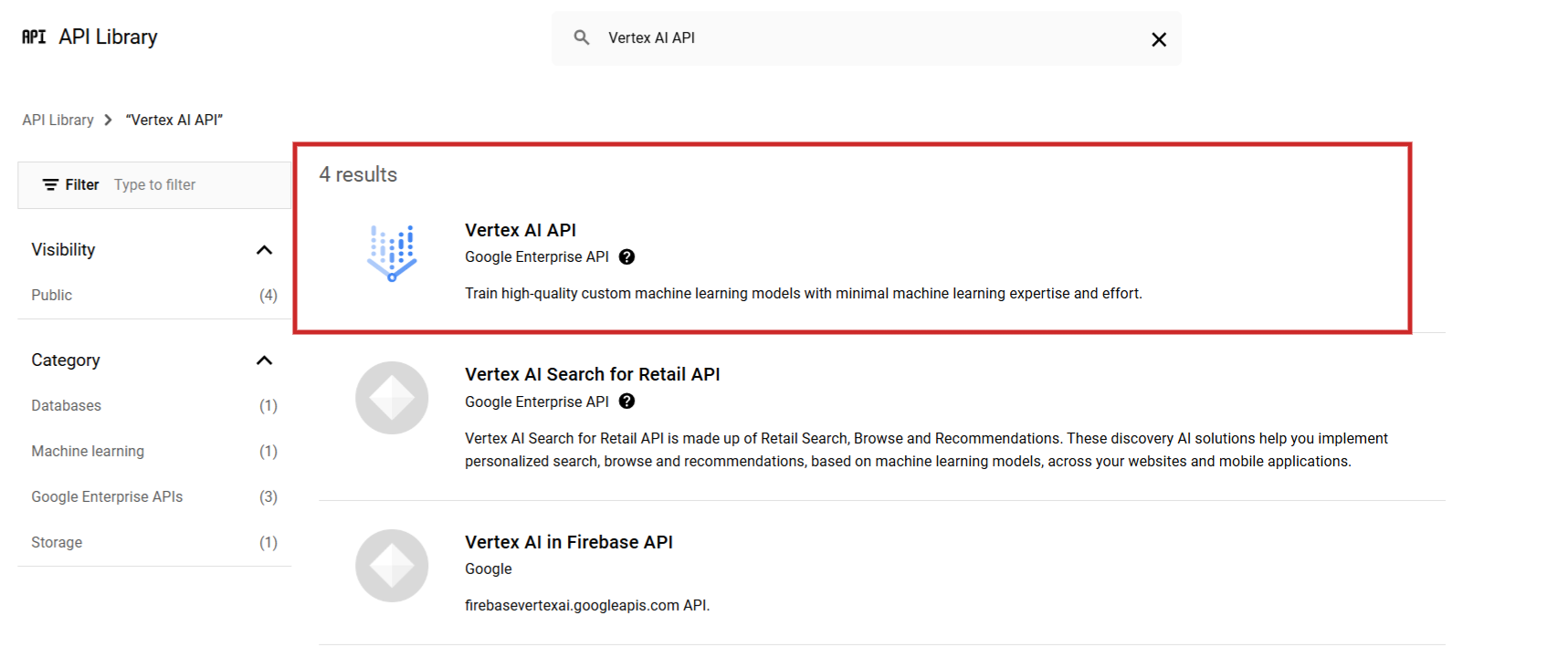 Screenshot from Google Cloud Console, December 2024
Screenshot from Google Cloud Console, December 2024Organize your billing account to have the flexibility to make use of Vertex AI as pricing is $0.0002 per 1,000 characters (and it presents $300 credit score for model new clients).
While you set it, it is worthwhile to navigate to API Corporations > Credentials create a service account, generate a key, and acquire them as JSON.
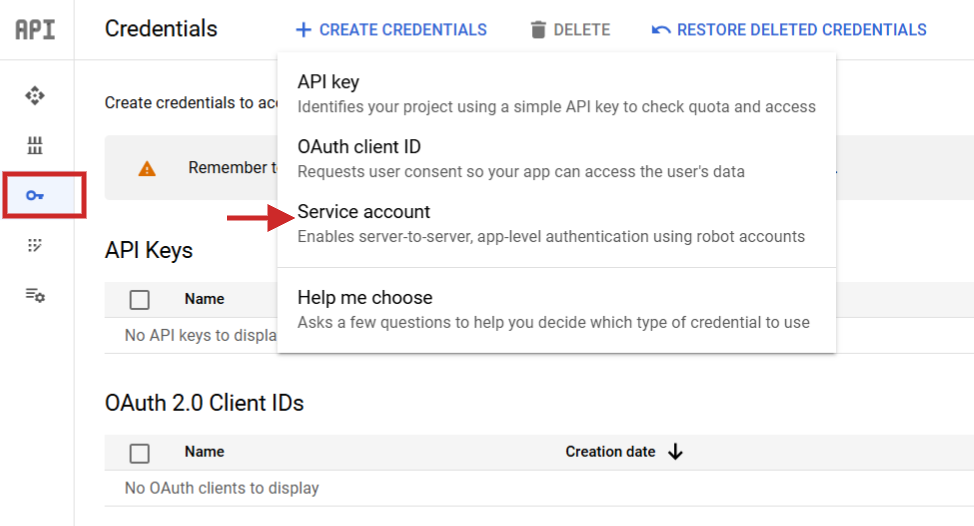
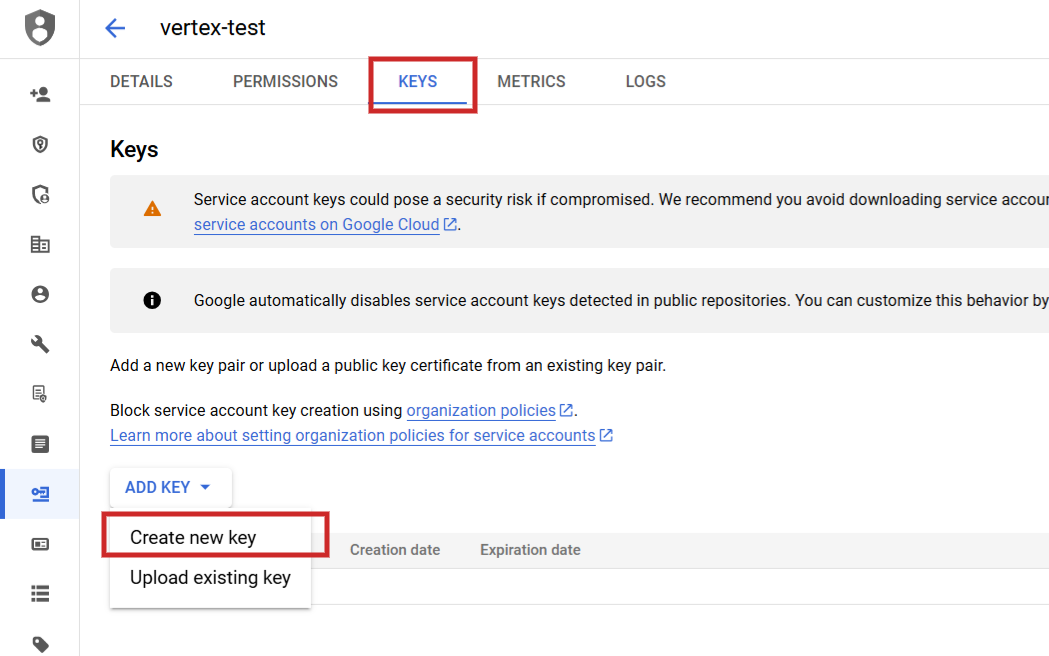

Rename the JSON file to config.json and add it (by means of the arrow up icon) to your Jupyter Pocket ebook problem folder.
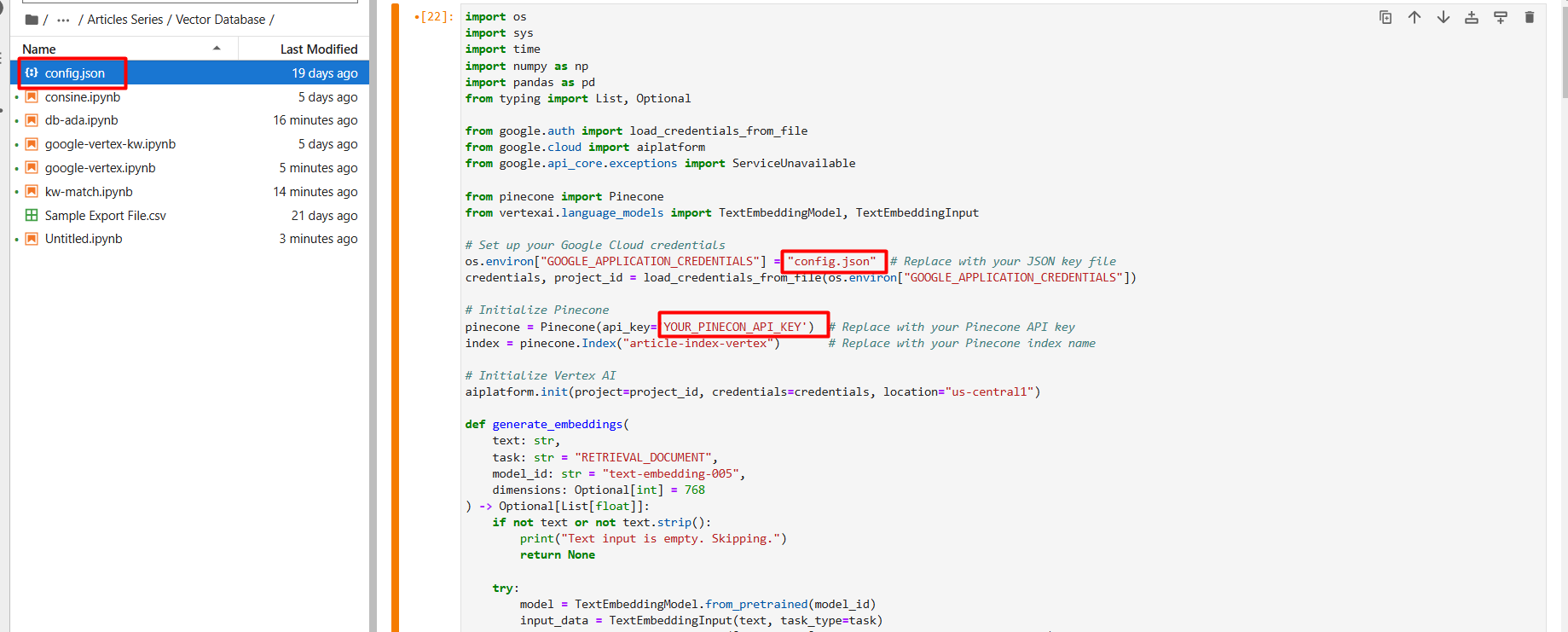 Screenshot from Google Cloud Console, December 2024
Screenshot from Google Cloud Console, December 2024Inside the setup first step, create a model new vector database generally known as article-index-vertex by setting dimension 768 manually.
As quickly as created you presumably can run this script to begin out producing vector embeddings from the the an identical sample file using Google Vertex AI text-embedding-005 model (you presumably can choose text-multilingual-embedding-002 while you’ve acquired non-English textual content material).
import os
import sys
import time
import numpy as np
import pandas as pd
from typing import File, Non-obligatory
from google.auth import load_credentials_from_file
from google.cloud import aiplatform
from google.api_core.exceptions import ServiceUnavailable
from pinecone import Pinecone
from vertexai.language_models import TextEmbeddingModel, TextEmbeddingInput
# Organize your Google Cloud credentials
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "config.json" # Substitute collectively together with your JSON key file
credentials, project_id = load_credentials_from_file(os.environ["GOOGLE_APPLICATION_CREDENTIALS"])
# Initialize Pinecone
pinecone = Pinecone(api_key='YOUR_PINECON_API_KEY') # Substitute collectively together with your Pinecone API key
index = pinecone.Index("article-index-vertex") # Substitute collectively together with your Pinecone index title
# Initialize Vertex AI
aiplatform.init(problem=project_id, credentials=credentials, location="us-central1")
def generate_embeddings(
textual content material: str,
exercise: str = "RETRIEVAL_DOCUMENT",
model_id: str = "text-embedding-005",
dimensions: Non-obligatory[int] = 768
) -> Non-obligatory[List[float]]:
if not textual content material or not textual content material.strip():
print("Textual content material enter is empty. Skipping.")
return None
try:
model = TextEmbeddingModel.from_pretrained(model_id)
input_data = TextEmbeddingInput(textual content material, task_type=exercise)
vectors = model.get_embeddings([input_data], output_dimensionality=dimensions)
return vectors[0].values
apart from ServiceUnavailable as e:
print(f"Vertex AI service is unavailable: {e}")
return None
apart from Exception as e:
print(f"Error producing embeddings: {e}")
return None
# Load data from CSV
data = pd.read_csv("Sample Export File.csv") # Substitute collectively together with your CSV file path
for idx, row in data.iterrows():
try:
permalink = str(row["Permalink"])
content material materials = row["Content"]
embedding = generate_embeddings(content material materials)
if not embedding:
print(f"Skipping article ID {row['ID']} ensuing from empty or failed embedding.")
proceed
print(f"Embedding for {permalink}: {embedding[:5]}...")
sys.stdout.flush()
index.upsert(vectors=[
(
permalink,
embedding,
{
'category': row['Category'],
'title': row['Title'],
'publish_date': row['Publish Date'],
'kind': row['Type'],
'publish_year': row['Publish Year']
}
)
])
time.sleep(1) # Non-obligatory: Sleep to stay away from cost limits
apart from Exception as e:
print(f"Error processing article ID {row['ID']}: {e}")
print("All embeddings are saved inside the vector database.")
You’ll notice beneath in logs of created embeddings.
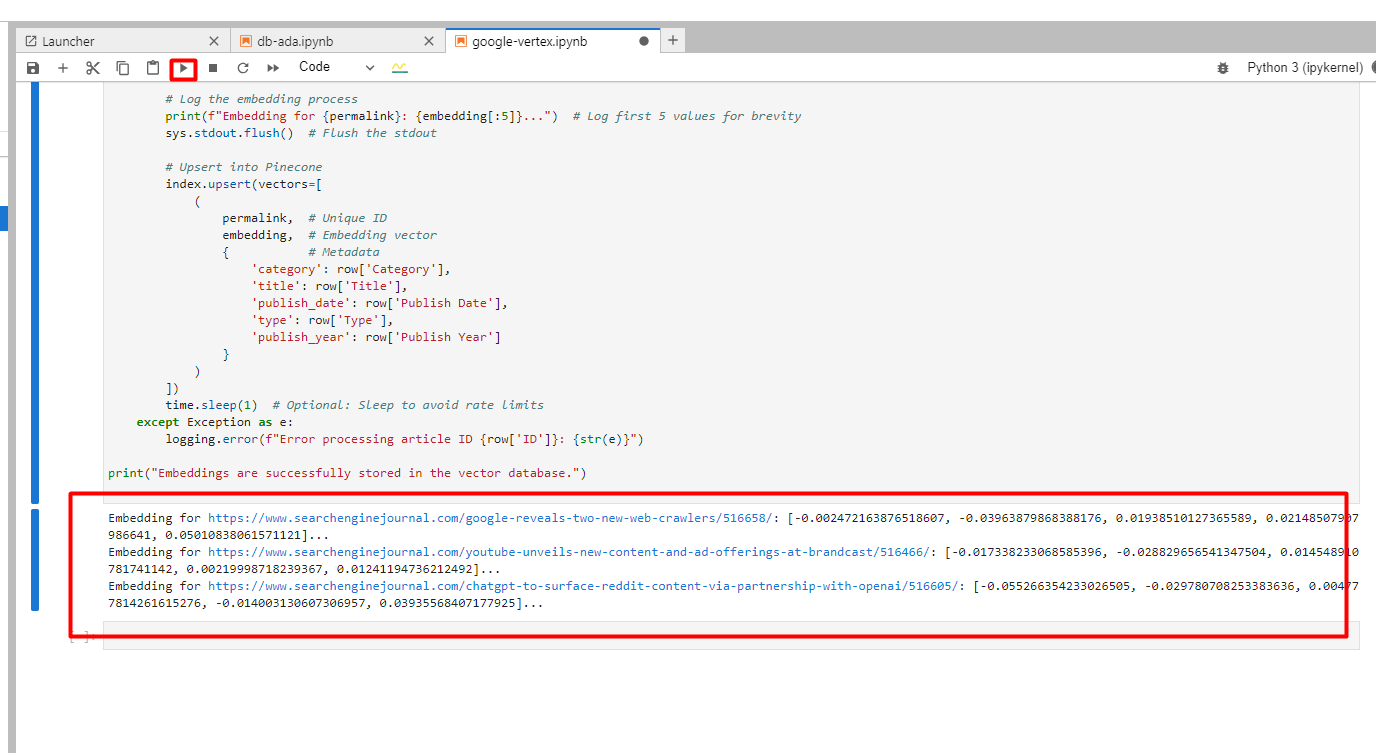 Screenshot from Google Cloud Console, December 2024
Screenshot from Google Cloud Console, December 20244. Discovering An Article Match For A Key phrase Using Google Vertex AI
Now, let’s do the an identical key phrase matching with Vertex AI. There is a small nuance because it’s worthwhile to make use of ‘RETRIEVAL_QUERY’ vs. ‘RETRIEVAL_DOCUMENT’ as an argument when producing embeddings of key phrases as we attempt to perform a search for an article (aka doc) that biggest matches our phrase.
Course of varieties are one in all many important advantages that Vertex AI has over OpenAI’s fashions.
It ensures that the embeddings seize the intent of the important thing phrases which is crucial for internal linking, and improves the relevance and accuracy of the matches current in your vector database.
Use this script for matching the important thing phrases to vectors.
import os
import pandas as pd
from google.cloud import aiplatform
from google.auth import load_credentials_from_file
from google.api_core.exceptions import ServiceUnavailable
from vertexai.language_models import TextEmbeddingModel
from pinecone import Pinecone
from tabulate import tabulate # For desk formatting
# Organize your Google Cloud credentials
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "config.json" # Substitute collectively together with your JSON key file
credentials, project_id = load_credentials_from_file(os.environ["GOOGLE_APPLICATION_CREDENTIALS"])
# Initialize Pinecone shopper
pinecone = Pinecone(api_key='YOUR_PINECON_API_KEY') # Add your Pinecone API key
index_name = "article-index-vertex" # Substitute collectively together with your Pinecone index title
index = pinecone.Index(index_name)
# Initialize Vertex AI
aiplatform.init(problem=project_id, credentials=credentials, location="us-central1")
def generate_embeddings(
textual content material: str,
model_id: str = "text-embedding-005"
) -> guidelines:
"""
Generates embeddings for the enter textual content material using Google Vertex AI's embedding model.
Returns None if textual content material is empty or an error occurs.
"""
if not textual content material or not textual content material.strip():
print("Textual content material enter is empty. Skipping.")
return None
try:
model = TextEmbeddingModel.from_pretrained(model_id)
vector = model.get_embeddings([text]) # Eradicated 'task_type' and 'output_dimensionality'
return vector[0].values
apart from ServiceUnavailable as e:
print(f"Vertex AI service is unavailable: {e}")
return None
apart from Exception as e:
print(f"Error producing embeddings: {e}")
return None
def match_keywords_to_index(key phrases):
"""
Matches a list of keyword-category pairs to the closest articles inside the Pinecone index,
filtering by metadata if specified.
"""
outcomes = []
for keyword_pair in key phrases:
key phrase = keyword_pair[0]
class = keyword_pair[1]
try:
keyword_vector = generate_embeddings(key phrase)
if not keyword_vector:
print(f"No embedding generated for key phrase '{key phrase}' at school '{class}'.")
outcomes.append({
'Key phrase': key phrase,
'Class': class,
'Match Score': 'Error/Empty',
'Title': 'No match',
'URL': 'N/A'
})
proceed
query_results = index.query(
vector=keyword_vector,
top_k=1,
include_metadata=True,
filter={"class": class}
)
if query_results['matches']:
closest_match = query_results['matches'][0]
outcomes.append({
'Key phrase': key phrase,
'Class': class,
'Match Score': f"{closest_match['score']:.2f}",
'Title': closest_match['metadata'].get('title', 'N/A'),
'URL': closest_match['id']
})
else:
outcomes.append({
'Key phrase': key phrase,
'Class': class,
'Match Score': 'N/A',
'Title': 'No match found',
'URL': 'N/A'
})
apart from Exception as e:
print(f"Error processing key phrase '{key phrase}' with class '{class}': {e}")
outcomes.append({
'Key phrase': key phrase,
'Class': class,
'Match Score': 'Error',
'Title': 'Error occurred',
'URL': 'N/A'
})
return outcomes
# Occasion utilization:
key phrases = [["SEO Tools", "Tools"], ["TikTok", "TikTok"], ["SEO Consultant", "SEO"]]
matches = match_keywords_to_index(key phrases)
# Present the ends in a desk
print(tabulate(matches, headers="keys", tablefmt="fancy_grid"))
And you’ll notice scores generated:
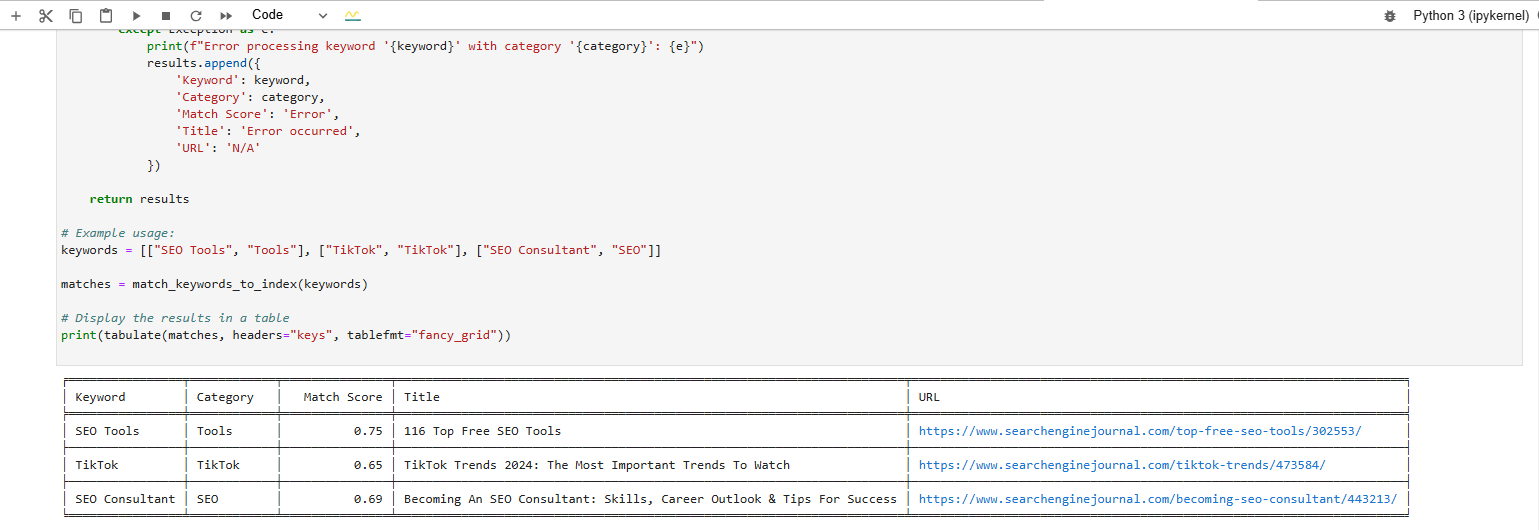 Key phrase Matche Scores produced by Vertex AI textual content material embedding model
Key phrase Matche Scores produced by Vertex AI textual content material embedding modelTry Testing The Relevance Of Your Article Writing
Take into account this as a simplified (broad) strategy to check how semantically associated your writing is to the highest key phrase. Create a vector embedding of your head key phrase and full article content material materials by means of Google’s Vertex AI and calculate a cosine similarity.
In case your textual content material is simply too prolonged you can need to ponder implementing chunking strategies.
An in depth ranking (cosine similarity) to 1.0 (like 0.8 or 0.7) means you’re pretty shut on that subject. In case your ranking is lower you can uncover that an excessively prolonged intro which has loads of fluff is also inflicting dilution of the relevance and decreasing it helps to increase it.
Nonetheless take into account, any edits made must make sense from an editorial and shopper experience perspective as successfully.
Chances are you’ll even do a quick comparability by embedding a competitor’s high-ranking content material materials and seeing the best way you stack up.
Doing this allows you to additional exactly align your content material materials with the objective subject, which might help you to rank greater.
There are already devices that perform such duties, nonetheless learning these experience means you presumably can take a customized technique tailored to your desires—and, in spite of everything, to do it completely free.
Experimenting in your self and learning these experience will help you to to take care of ahead with AI SEO and to make educated selections.
As additional readings, I prefer to advocate you dive into these good articles:
Additional property:
Featured Image: Aozorastock/Shutterstock